










 AI智能应用开发
AI智能应用开发 AI大模型开发(Python)
AI大模型开发(Python) AI鸿蒙开发
AI鸿蒙开发 AI嵌入式+机器人开发
AI嵌入式+机器人开发 AI运维
AI运维 AI测试
AI测试 跨境电商运营
跨境电商运营 AI设计
AI设计 AI视频创作与直播运营
AI视频创作与直播运营 微短剧拍摄剪辑
微短剧拍摄剪辑 C/C++
C/C++ 狂野架构师
狂野架构师


数据分析怎样进行数据清洗?【详细讲解】
更新时间:2022年08月30日18时30分 来源:传智教育 浏览次数:

数据清洗的基本流程一共分为5个步骤,分别是数据分析、定义数据清洗的策略和规则、搜寻并确定错误实例、纠正发现的错误以及干净数据回流。下面通过一张图描述数据清洗的基本流程,具体如图所示。
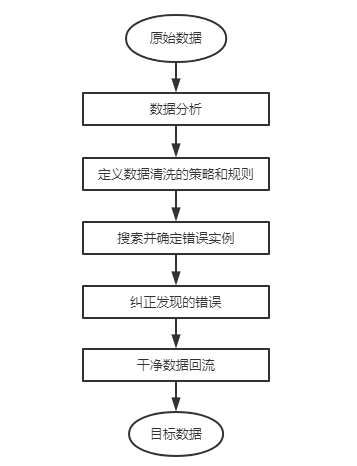
接下来针对图中数据清洗的基本流程进行详细讲解。
1.数据分析
数据分析是数据清洗的前提和基础,通过人工检测或者计算机分析程序的方式对原始数据源的数据进行检测分析,从而得出原始数据源中存在的数据质量问题。
2.定义数据清洗的策略和规则
根据数据分析出的数据源个数和数据源中的“脏”数据程度定义数据清洗策略和规则,并选择合适的数据清洗算法。
3.搜寻并确定错误实例
搜寻并确定错误实例步骤包括自动检测属性错误和检测重复记录的算法。
手工检测数据集中的属性错误需要花费大量的时间、精力以及物力,并且该过程本身很容易出错,所以需要使用高效的方法自动检测数据集中的属性错误,主要检测方法有基于统计的方法、聚类方法和关联规则方法。
检测重复记录的算法可以对两个数据集或者一个合并后的数据集进行检测,从而确定同一个现实实体的重复记录,即匹配过程。检测重复记录的算法有基本的字段匹配算法、递归字段匹配算法等。
4.纠正发现的错误
根据不同的“脏”数据存在形式的不同,执行相应的数据清洗和转换步骤解决原始数据源中存在的质量问题。需要注意的是,对原始数据源进行数据清洗时,应该将原始数据源进行备份,以防需要撤销清洗操作。
为了便于处理单数据源、多数据源以及单数据源与其他数据源合并的数据质量问题,一般需要在各个数据源上进行数据转换操作,具体如下。
(1)从原始数据源的属性字段中抽取值(属性分离)
原始数据源的属性一般包含很多信息,这些信息有时需要细化成多个属性,便于后续清洗重复记录。
(2)确认并改正
确认并改正输入和拼写的错误,然后尽可能地使该步骤自动化。若是基于字典查询拼写错误,则更利于发现拼写的错误。
(3)标准化
为了便于记录实例匹配和合并,应该将属性值转换成统一格式。
5.干净数据回流
当数据被清洗后,干净的数据替代原始数据源中的“脏”数据,这样可以提高信息系统的数据质量,还可避免将来再次抽取数据后进行重复的清洗工作。
最新资讯




















江苏传智播客教育科技股份有限公司 版权所有Copyright 2006-2024 All
Rights Reserved
苏ICP备16007882号营业执照增值电信业务经营许可证出版物经营许可证 苏公网安备 32132202001156号
苏公网安备 32132202001156号
免费领取黑马程序员AI通道专属星级课程资料
