










 AI智能应用开发
AI智能应用开发 AI大模型开发(Python)
AI大模型开发(Python) AI鸿蒙开发
AI鸿蒙开发 AI嵌入式+机器人开发
AI嵌入式+机器人开发 AI运维
AI运维 AI测试
AI测试 跨境电商运营
跨境电商运营 AI设计
AI设计 AI视频创作与直播运营
AI视频创作与直播运营 微短剧拍摄剪辑
微短剧拍摄剪辑 C/C++
C/C++ 狂野架构师
狂野架构师


卡方检验的原理和实现方法
更新时间:2020年08月07日15时24分 来源:传智播客 浏览次数:
学习目标
掌握卡方检验的原理和实现
卡方检验用来分析两个名义变量之间是否显著相关。
学了这么多连续变量的统计分析,那么对于计数资料可咋整。小伙伴会问了:如果我想看不同患者人群的术后复发率有没有差异,怎么办?这时候就需要欢迎我们的统计小助手——卡方检验闪亮登场啦!
卡方检验可是一位重量级选手,凡是涉及到计数资料分布的比较都需要他的帮忙。
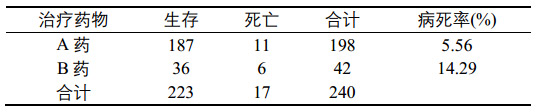
用药物A治疗急性心肌梗死患者198例,24小时内死亡11例,病死率为5.56%,另42例治疗时采用药物B,24小时内死亡6例,病死率为14.29%,提问:两组病死率有无差别?
表1. 两种药物急性心肌梗塞患者治疗后24小时内死亡情况。
卡方检验的目的:确定样本对象落入各类别的比例是否与随机期望比例相等。
1.卡方值计算

两个概念
·观测频数
·预期频数
计算各行和各列的和:
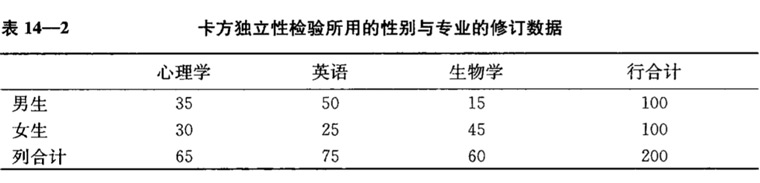
计算每个格子在当前行中的预期频数
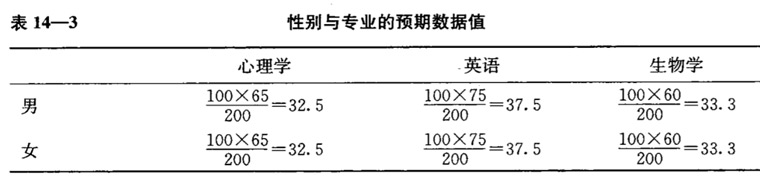
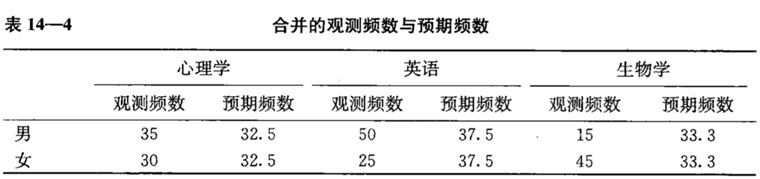
列出每个格子的观测频数和预期频数
卡方值的计算公式:
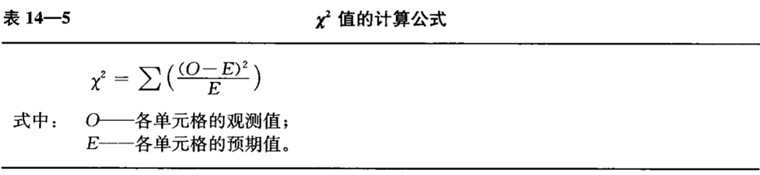
计算每个格子的值:
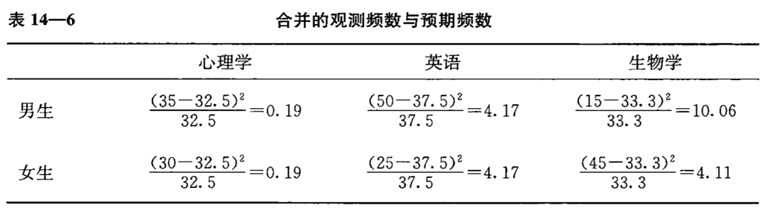
最终 $$\chi^2$$=0.19+4.17+10.06+0.19+4.17+4.11=22.89
自由度$df=(R-1)(C-1)=(2-1)(3-1)=2$
结论

2.代码实现
手动代码实现:
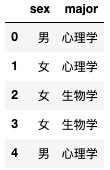
·导入数据
import pandas as pd
data=pd.read_csv('data/chi2.csv')
data.head()
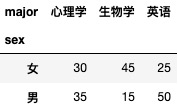
·统计频次(交叉表统计)
#统计频次
table=pd.crosstab(data['sex'],data['major'])
table
·计算预期频次
#计算预期频次
x=o.values
col=np.sum(x,axis=1,keepdims=True)#行的和
row=np.sum(x,axis=0,keepdims=True)#列的和
total=np.sum(x)#总和
col,row,total

e=col*row/total#计算预期频次
e
·计算卡方值
#计算卡方值
o_miuns_e=o.values-e #o-e
chi2=np.sum(np.square(o_miuns_e)/e)
chi2
·计算p值
#计算p值
df=(o.shape[0]-1)*(o.shape[1]-1)#自由度
p=1-ss.chi2.cdf(chi2,df)
p#7.074778948346072e-06 拒绝原假设 专业选择和性别之间相关
·scipy实现:
Api:scipy.stats.chi2_contingency(observed):
·参数:
observed:观测的实际频次 通常为$$R\times C$$的表格
·返回值:
chi2:卡方值
p:p值
dof:自由度
expected:预期频次
代码实现
·加载数据
import pandas as pd
import scipy.stats as ss
data=pd.read_csv('data/chi2.csv')
data.head()
·统计观测频次
#统计频次
o=pd.crosstab(data['sex'],data['major'])
o
·卡方检验
chi2,p,dof,e=ss.chi2_contingency(o)
chi2,p,dof,e
(23.71794871794872, 7.0747789483371884e-06, 2, array([[32.5, 30. , 37.5],[32.5, 30. , 37.5]]))
3.小结
·卡方检验:用来分析两个名义变量之间是否显著相关
·卡方值计算:
观测频次O
预期频次E
自由度:$$(R-1)\times(C-1)$$
api:scipy.stats.chi2_contingency(observed)
猜你喜欢:
什么是RNN?RNN可以做什么?
最新资讯




















江苏传智播客教育科技股份有限公司 版权所有Copyright 2006-2024 All
Rights Reserved
苏ICP备16007882号营业执照增值电信业务经营许可证出版物经营许可证 苏公网安备 32132202001156号
苏公网安备 32132202001156号
免费领取黑马程序员AI通道专属星级课程资料
